Benford's Law Tests for Wikileaks Data
In my first post on the WL Afghanistan data I provided a very high-level view of the data, and found that it generally met expectations for frequency given its context and presumed data generating process. Next, I will look a bit deeper at this process and test if the observed frequencies of reports have properties consistent with a natural data generating process. I will be using Benford's Law to test if the leading digit of weekly report counts follow's Benford's distribution. Benford's Law is often used to test for fraud or tampering in count data. In fact, two professor's in the Politics department at NYU used the test to uncover fraud in the 2009 Iranian presidential election.
Rather than vote counts, however, I will be counting the number of reports observed every week in the data set, which amounts to 318 weeks of count data. This is of particular interest to this data because we may be able to provide evidence that the data were altered from their original collection. After the jump is a visualization of this test for the total data set, but before proceeding there are two important things to keep in mind. First, this is not the most straightforward application of Benford's Law, as the data had to be compacted and counted to get into a suitable form (e.g., split into weeks, etc.). Second, given that these date are leaked intelligence reports, we should expect there to be so degree of selection, but the test is not able to show where that selection occurred—only that it did.

Using the weekly time-slices as counts, plots shows some tampering or selection may have occurred. The Pr(1) in the observed data set is much lower than the theoretical expectation provided by Benford, and moving forward along the x-axis the observed data slowly return to the theoretical expectation. Also, as suggested in the comments, I used a chi-square goodness-of-fit test to see if the deviation is statistically significant, but it was not; with a p-value of 0.2303. Meaning we would fail to reject the null hypothesis: the observed data were a good fit for a Benford process. That said, the p-value is not so large as to suggest total adherence.
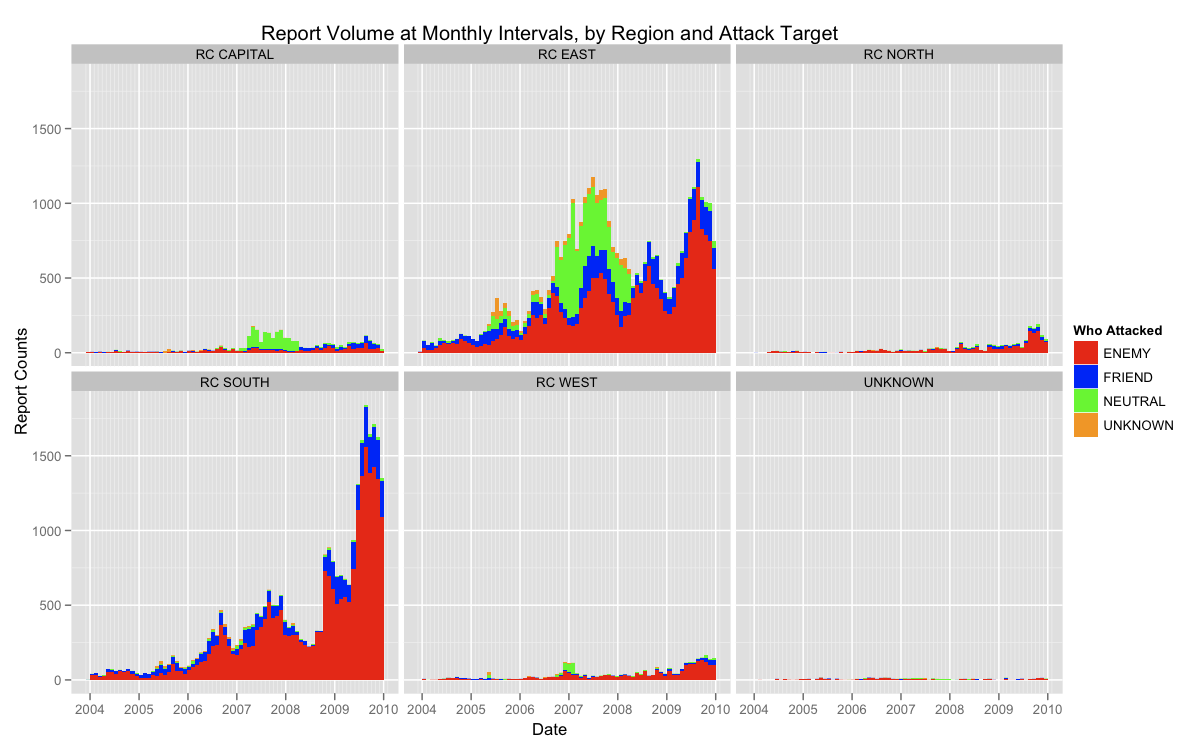
Also, the above analysis does not provide insight into where that deviation occurs within the data. Also, One way to investigate the later question would be to split the data out by region, and then re-run the test. This might help isolate where the tampering occurred, as would be the case if the test were being applied to vote counts by precinct, etc. Below is a visualization of this more detailed test.

This test is much more revealing. Here we can see that many of the regions follow Benford's law very closely—particularly RC SOUTH and RC WEST. There are, however, slight deviations in the RC EAST and UNKNOWN. Though not nearly as strong a deviation as the total set, the observation from RC is interesting given that we know from the previous analysis that this is also the area with the heaviest reporting volume. The chi-square test for these data also reject the null hypothesis.
Overall, this test does not provide strong evidence for tampering with the data, but it does indicate that some may have occurred, perhaps disproportionately in data from RC EAST. Finally, I have opened a Git repository for this analysis, so you may go there to see how these (and previous/future) analyses were performed.