

Building a Better Word Cloud
A few weeks ago I attended the NYC Data Visualization and Infographics meetup, which included a talk by Junk Charts blogger Kaiser Fung. Given the topic of his blog, I was a bit shocked that the central theme of his talk was comparing good and bad word clouds. He even stated that the word cloud was one of the best data visualizations of the last several years. I do not think there is such a thing as a good word cloud, and after the meetup I left unconvinced; as evidenced by the above tweet.
This tweet precipitated a brief Twitter debate about the value of word clouds, but from that straw poll it seemed the Nays had the majority. My primary gripe is that space is meaningless in word clouds. They are meant to summarize a single statistics—word frequency—yet they use a two dimensional space to express that. This is frustrating, since it is very easy to abuse the flexibility of these dimensions and conflate the position of a word with its frequency to convey dubious significance.
Since then, I have been inundated with word clouds. The State of the Union address always brings out a wave of word clouds. Even LinkedIn got in on the action with this spinning word cloud of doom. I'd had enough, and decided it was time to add spatial meaning to the lexical cauldron of word clouds, and see how far I could get.
First, I was struck by one of the comments at the NYVIZ meetup. An audience member mentioned to Kaiser that the word clouds he found most useful were those presented as comparison; i.e., comparing word clouds from two different texts on similar topics. This appealed to my statistical inclinations, wherein we are often interested in comparing data. As such, I decided that the best way to evolve the word cloud was to create one that compared two texts in a single visualization. Given the timeframe when this pet project started, the data I sought to compare were the speeches given by Pres. Obama and Sarah Palin in the wake of the Tucson shooting.
This is the result of my effort to build a better word cloud...
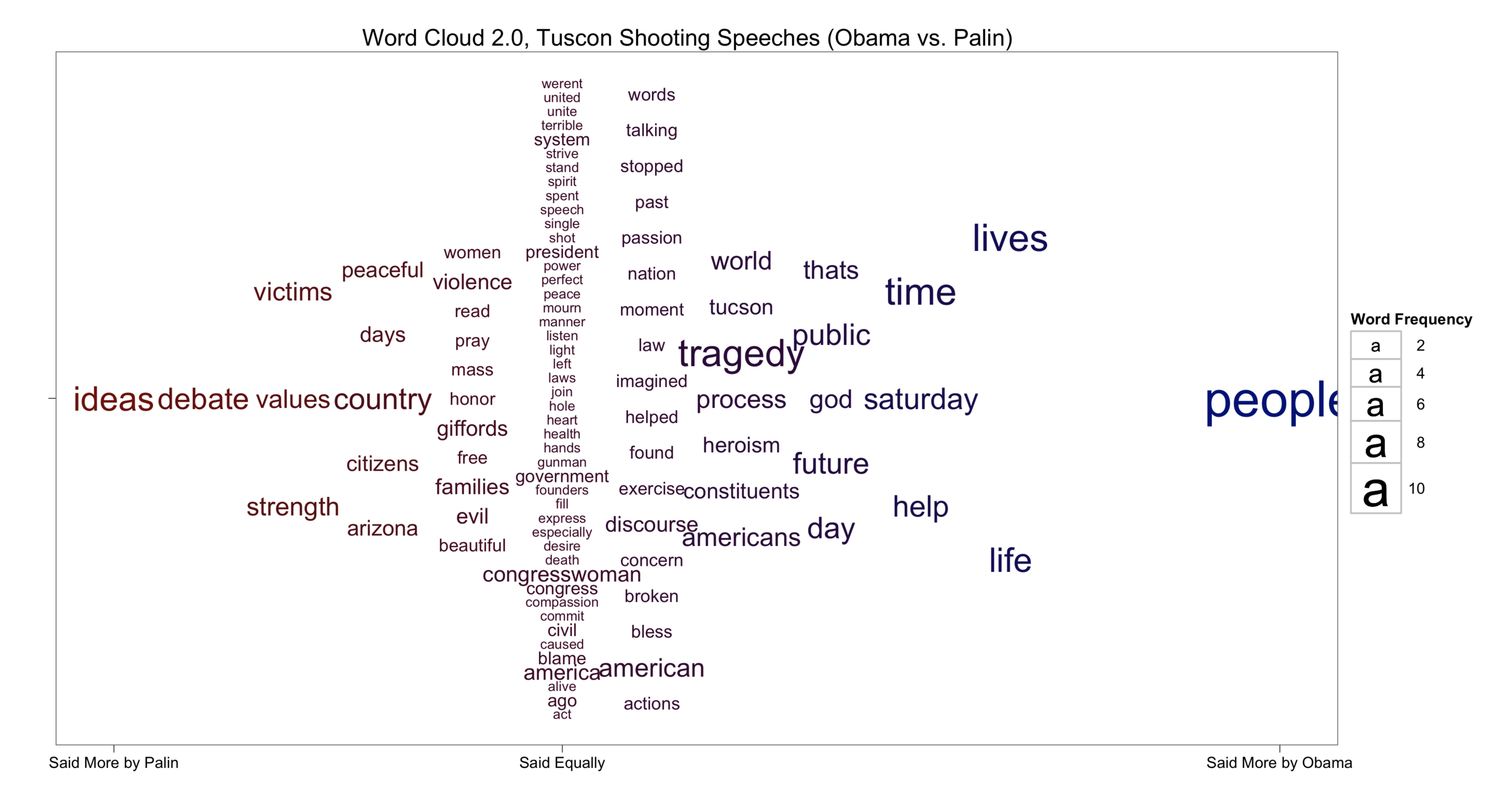
The best data visualizations should stand on their own, which is why I present the word cloud before explaining how I created it. What do you think?
To understand how these speeches compared I first needed to create a term-frequency matrix, which contained only words used in both speeches. After removing common English stop words and the word 'applause' (Obama's speech was in front of a live audience), and retaining only words contained in both speeches at least once, I was left with 103 words to visualize.
To show how the two speeches contrasted, I decided to use the x-axis position to pull words used more by one politician closer to either the left or right of the plot. Words used more by Palin are to the left, and likewise words to the right were used more by Obama. The color reinforces this information, making words Palin words darker red, and Obama darker blue. The scaling of the x-axis is also very important. Note that the "Said Equally" partition does not appear at the exact center of the graph—this is intentional. The word "people" is said more by Obama than any shared word in the corpus. The variance in distance between the equal partition and the edges of the plot is meant to convey this disparity.
Next, I wanted to improve the word cloud, but not redefine it. The base motivation of a word cloud is to convey term frequency by the word size, therefore, this remains true here. In this case, however, because there are two different frequency counts for each text some reduction in data must be used to fit the data into a single visualization. To accomplish this, those words used more often by either politician are sized based on the frequency of the word in that politician's speech. For example, both Obama and Palin use the word "violence," but Palin uses it more; therefore, that word is sized by its frequency in her speech. Logically, words at in the equal partition are sized by their frequency in both speeches.
For the y-axis I wanted to maximize readability. One of the most frustrating things about traditional word clouds is how hard they make you work to read the words. As such, I created a simple function that equally spaced the words on the y-axis given the number appearing in each vertical partition. It isn't perfect, but for this relatively small number of words all are reasonably visible. Also, the ordering from top to bottom is simply the descending alphabetical order of each vertical partition.
While this is a very simple extension of the traditional word cloud, much more can be learned from it. For example, both politicians used the words "congresswomen," and "america" equally but also frequently. While the word "tragedy" is used often in both speeches, but slightly more by Obama. The edges are most interesting. Palin repeated the shared terms "ideas," "debate," "victims," "values," and "strength," while Obama focused on "people," "lives," and "life."
A clear weakness in this approach is that words that are not in the intersection of two texts are ignored. In an effort for full democratization of methods for visualizing word frequency, below are the Wordle versions of the texts used to create the above visualization. They are presented side-by-side to allow for comparison.

Palin Wordle

Obama Wordle
Finally, as you may have guessed, this visualization was created in R using a combination of the tm and ggplot2 packages. The data and code are available in the ZIA Code Repository for your amusement.
So, which method do you like better?